 |
PandA-2024.02
|
|
PandA-2024.02
|
TODO: add a part about graph created starting from c short circuits
Language based specification usually are translated into intermediate representations to efficiently manage and analyze the design specification. Panda as intermediate representation uses different types of graph. They can be divided into two main class:
For many of these types of graphs there are two different version: the first hasn't feedback edges, the second does. An edge is of feedback type if it closes a cycle in some path starting from ENTRY.
In following subsection all types will be more accurately described and it will be given the correspondent graph of the following example:
1 a = 1;
2 b = 2;
3 c = 3;
4 d = 0;
5 a = a + b;
6 e = a == b;
7 if (e)
{
8 c = a + b;
do
{
9 h = c + d;
10 c = c + 1;
11 d = d + 1;
12 g = c + d;
13 f = d !=c ;
}
14 while(f);
}
15 c = c + d;
16 c = c + 1;
The control flow graph represents the sequencing of the operations as described in the language specification. The CFG is a directed graph whose vertexes are represented by set V = {  ; i = 1, 2, ... ,
; i = 1, 2, ... ,  }. The set of edges is E = {( ,
}. The set of edges is E = {( ,  ); i , j = 1, 2, ... , }. It takes into account all constructs that cause a re-direction of the computational flow, such as branch statements, loop statements, jump statements, etc. The advantages of this representation is that it is quite simple to extract from the system specification even if it does not express the potential parallelism of the operations.
); i , j = 1, 2, ... , }. It takes into account all constructs that cause a re-direction of the computational flow, such as branch statements, loop statements, jump statements, etc. The advantages of this representation is that it is quite simple to extract from the system specification even if it does not express the potential parallelism of the operations.
On the other side one of the main disadvantages is that CFG generation for multi-process systems specifications does not appear to be simple, since a CFG has to manage at the same time all the flows of control of all the processes that compose the system. Thus the CFG model results intrinsically suitable just for single-process descriptions.
Some of the algorithms and tools which work on graph in PandA assume that the only type of cycle construct present in specification is the repeat-until. So if in specification some while-construct is present, it will be transformed into a "if repeat until" structure.
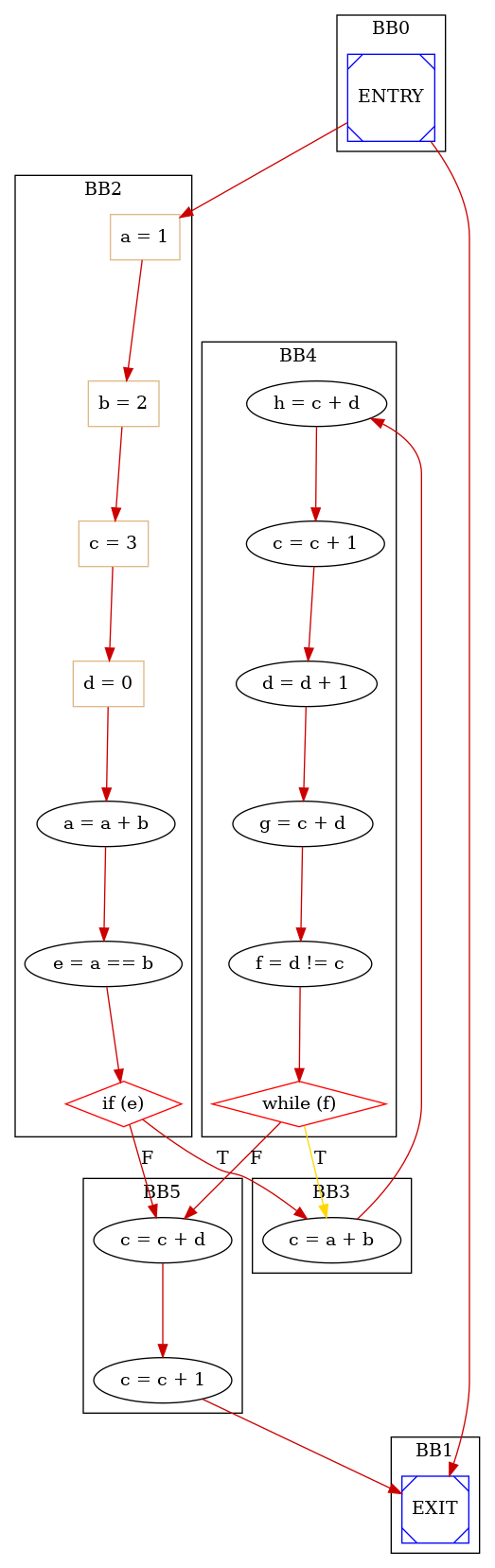
An example of CFG is:
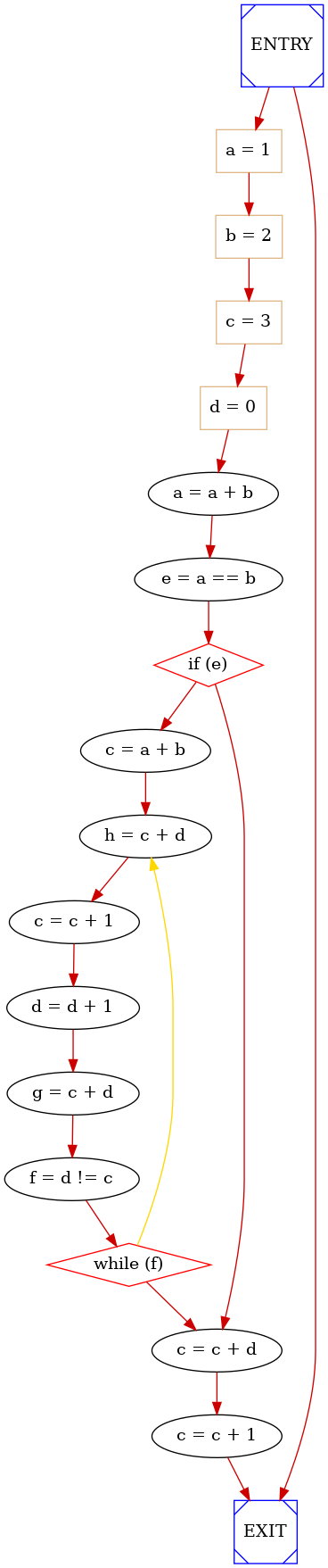
As you can see diamond nodes represent selection operations (e.g. TYPE_IF nodes), box nodes represent assignmente operations and square boxes represent special operations (ENTRY, EXIT and functions call which are not present in the given simple example)
The Control-Dependence graph represents control dependencies within operations, e. g. from which operation the excution of a single operation is controlled. We say that a node y is control-dependent on x if in CFG (for the moment we do not consider control flow feedback edges) from x we can branch to u or v; from u there is a path to exit that avoids y, and from v every path to exit hists y:
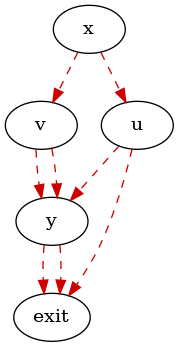
The CDG used in PandA has not only an edge between every pair (x,y) where y is control-dependent on x, but also from every node belonging to a cycle to ifs at the end of that cycle. In this mode we forced the check of the condition of the loop to be executed after all the operation of the cycles.
Moreover the in case of loop we also add some control dependence feedback edges: there is a control dependence feedback edge from every if which ends the loop to all operation which starts a new flow in the loop body, e. g. each operation which has control or data dependence only from operations external to loop body. An example of CDG is:
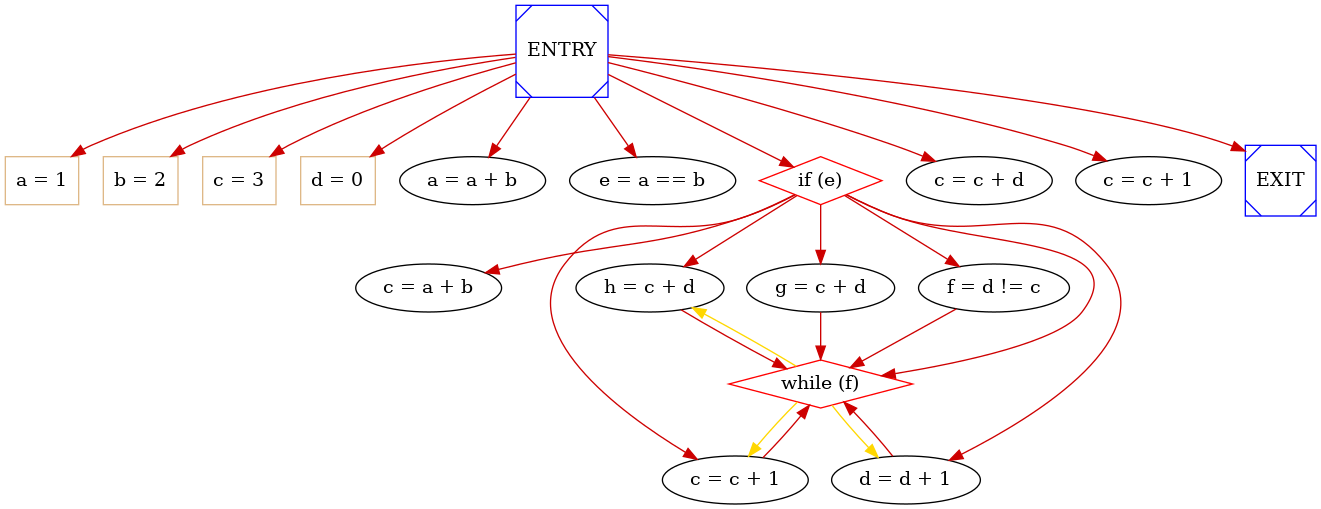
The data flow graph represents operations and data dependencies only of type read after write. A DFG is a directed graph whose vertexes are represented by the set V = { ; i = 1, 2, ... , }, where is the number of operations. The set of edges E = {( , ); i , j = 1, 2, ... , } represents the data transfer from an operation to another one. The DFG model implicitly assumes the existence of variables, that store the information required and generated by the operations. Each variable has a lifetime and the model assumes that the values of the variables are preserved during their lifetime. The lifetime of a variable is the interval from the birth and the death of the variable. The birth is the time at which the value is generated as output of an operation, the death is the latest time at which the variable is used as input to an operation. An Example of DFG is:
The Anti-dependence-graph represents operations and data dependencies of type write after write and write after read. These dependencies assure that variable reading and writing follows strict consistency model. Note that if in the original specification there are two writes (definitions) of the same variable and there isn't a use of the first definition, in the PandA representation the first operation does not write the variable, so in this case the Anti-dependence will not be added. The problem of variable consistency model and then the problem of Anti-dependencies are present only in case of not using SSA (Static Single Assingment) form: if we use it there are no more anti-dependencies.
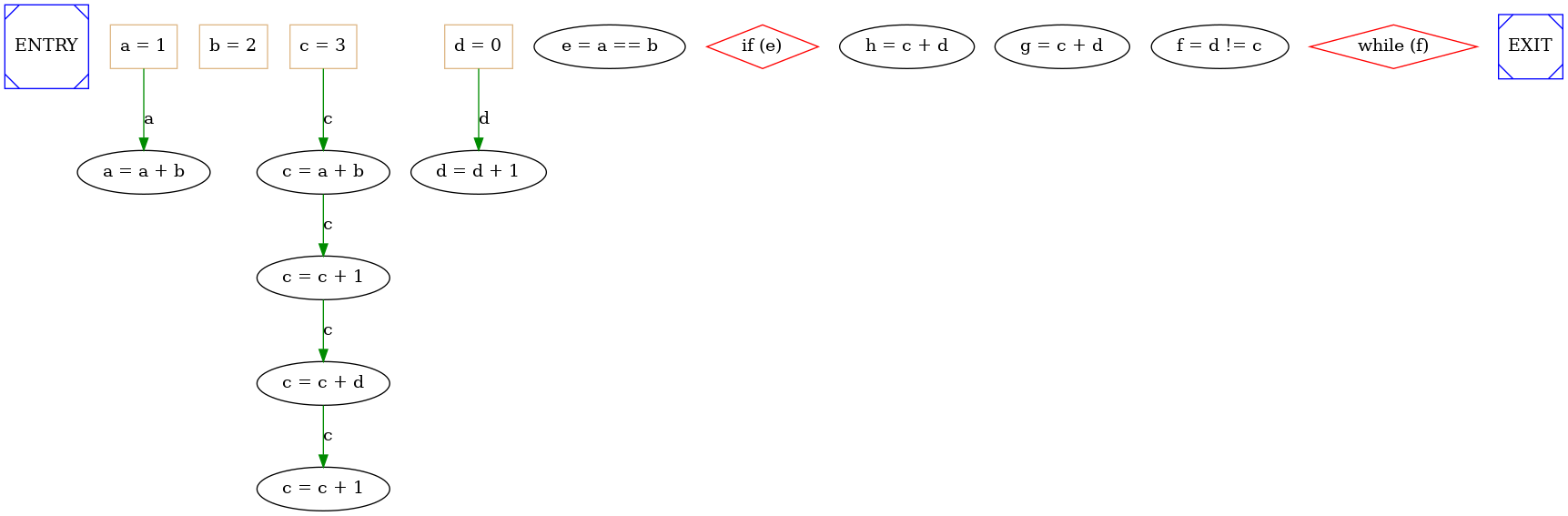
The System dependence graph is the fusion of two graphs: Control-dependence graph and Data-flow graph. It's useful because it represents both data and control dependence in an unique graph, but it does not contain futher precedences which are not real like control flow graph ones. It doesn't no represent Anti-dependencies so it can be used by scheduling algorithms only if we are using SSA form. An example of SDG is:
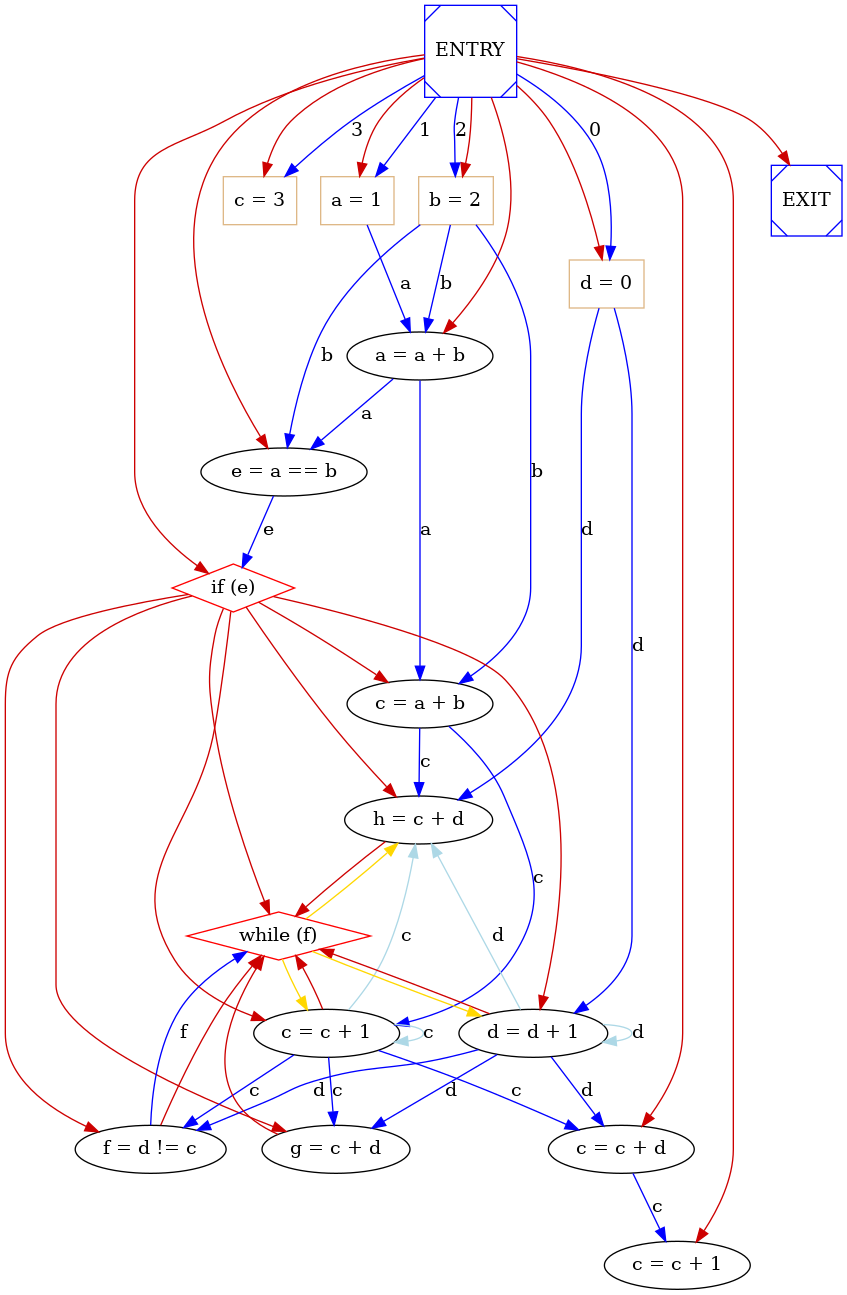
The System dependence and anti-dependence graph is the fusion of three different graph: control dependence graph, data flow graph and Anti-dependence graph. For this reason it reperesents all type of dependence and precedence between operations and it can be used by scheduling alghorithm in order to compute scheduling. An example of SADG is:
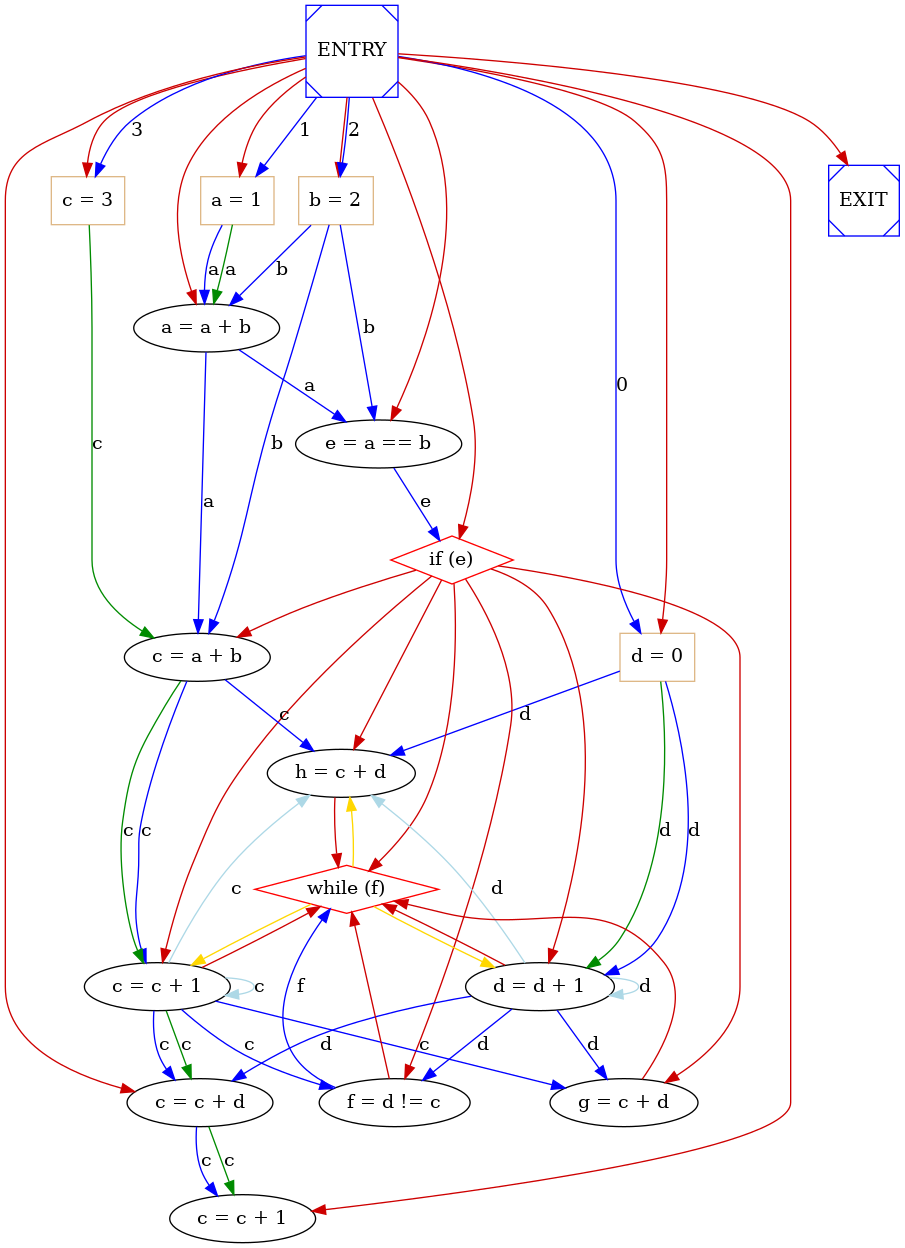
Speculation graph is a modified version of SADG where some control constraints are relaxed in order to permit control speculation in scheduling. This type of speculation consists in executing operations controlled by a controll construct like an if before that if condition and so the target of the control flow execution is computed. Doing this it is possible executing the specification in less time but it is also possible that more functional unit and a more complex controller is required in order to permit this techinique. In order to limitate the depth of speculation, it's possible only to anticipate the execution of operations which directly dependes by a control construct but it is not possible to anticipate the execution of operation which depends inderectly by a chain control dependence plus other type of dependence (data or anti-dependence). An example of SG is:
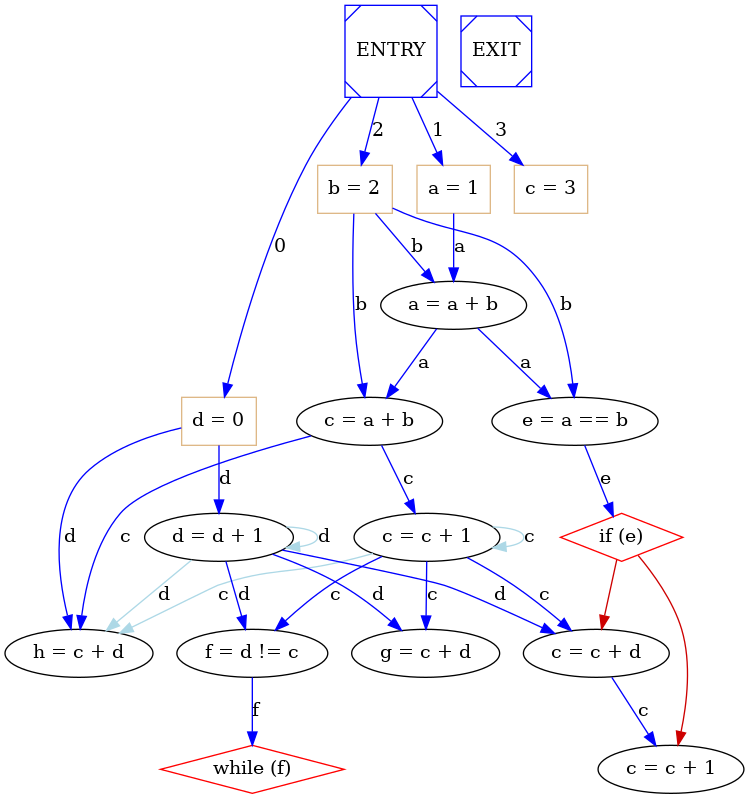
A Basic Block is a sequence of operations that is always entered at the beginning and exited at the end, that is: -the first statement is a Label, e. g. a possible target of a jump; -the last statement is a conditional jump, e. g. a control construct; -there are no other labels or jumps. Basic blocks are usually the basic unit to which compiler optimizations are applied in compiler theory, because if during the execution the first operation of basic block is executed, all operations belonging to the same basic block will be executed.
Instructions which begin a new basic block include:
Instructions that end a basic block include:
The Control flow graph of Basic Block is like previously described Control flow graph but the vertices instead of single operation are basic blocks. So in the version with feedback edges of this particular type of graphs it is not possible that a vertex has only one edge ingoing and a vertex has only one edge outgoing. The blocks to which control may transfer after reaching the end of a block are called that block's successors, while the blocks from which control may have come when entering a block are called that block's predecessors.
The algorithm for generating basic blocks from a listing of code is simple: you scan over the code, marking block boundaries, which are instructions which may either begin or end a block because they either transfer control or accept control from another point. Then, the listing is simply "cut" at each of these points, and basic blocks remain. Note that this method does not always generate maximal basic blocks, by the formal definition, but they are usually sufficient.
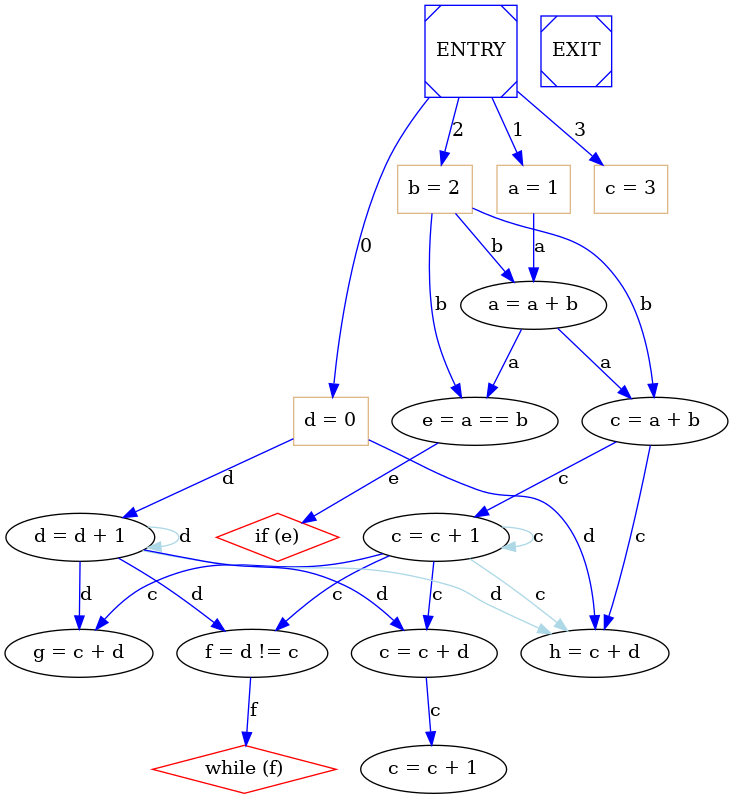
An example of BB Control Flow Graph is:
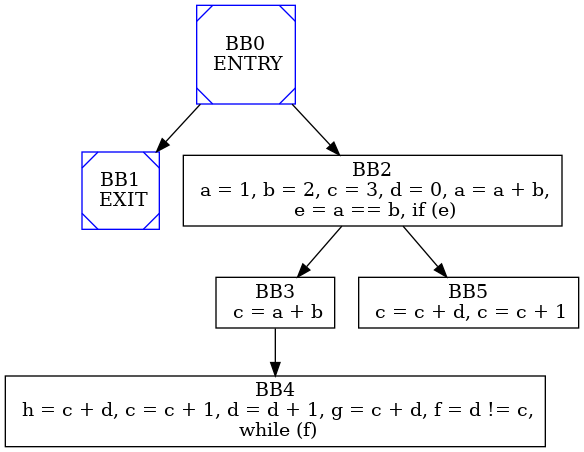
In computer science, in compilers, a dominator is an object which is always executed before another object, where the object is typically either a statement or a basic block. By definition an object dominates itself as well. A block M dominates a block N if every path from the entry that reaches block N has to pass through block M. The entry block dominates all blocks. Note that an object may have many dominators. Sometimes more useful is the concept of an immediate dominator, which is the unique object that dominates an object, while not dominating any other dominator of the object. A block M immediately dominates a block N if M dominates N, and there is no intervening block P such that M dominates P and P dominates N . In other words, M is the last dominator on any path from entry to N . Each block has a unique immediate dominator, if it has any at all. In the Basic Block Control flow graph used in Panda every blocks but ENTRY has an immediate dominator.
The dominator tree is an ancillary data structure where each object's parent is its immediate dominator. There is an arc from block M to block N if M is an immediate dominator of N. This graph is a tree, since each block has a unique immediate dominator. This tree is rooted at the entry block.
The dominators tree can be performed by using the Cooper algorithm [Keith D. Cooper, Timothy J. Harvey, Ken Kennedy, A Simple, Fast Dominance Algorithm, Software Practice and Experience, 2001.], which is basically an iterative algorithm adopting some refinements in the data structures used. At a later stage it could be substituted with a more efficient one, like the algorithm of Lengauer and Tarjan.
An example of dominator tree built from the Basic Block CFG is:
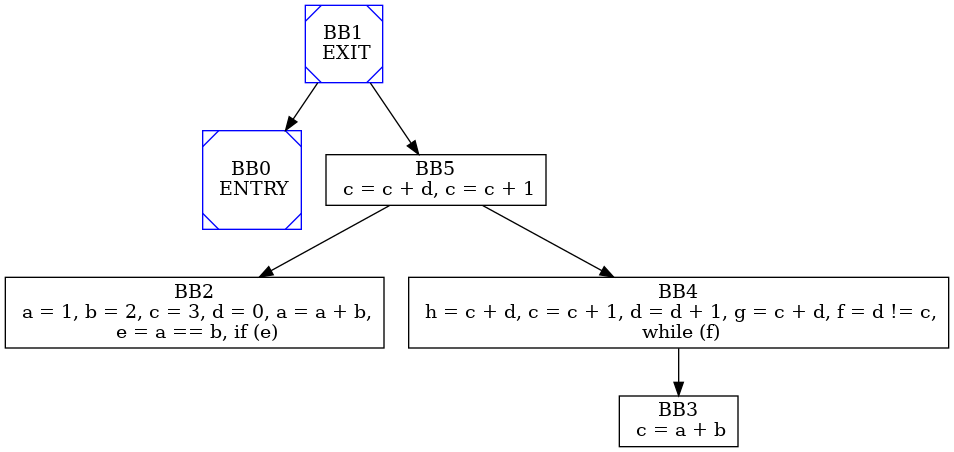
The relationship of post-dominance is the dual of dominance relation: we say that y postdominates v when y is on every path fro v to EXIT. Following the dualism with dominance relationship it is possible to define the immediate post-dominance relationship and then to build the Post Dominator tree.
An example of Post-dominator tree built from Basic Block CFG is:
 1.8.13
1.8.13