 |
PandA-2024.02
|
|
PandA-2024.02
|
PandA project aims at providing an open-source framework covering different aspects of the hardware - software design of embedded systems. PandA supports the research of new ideas on hardware design starting from logic to high-level synthesis on architectures integrating reconfigurable hardware and on embedded system design considering early performance estimation and optimization, including automatic parallelization, mapping and scheduling.
The current research program considers the following topics:
MultiProcessor systems are becoming more and more common, not only in the high performance segment, but also in the consumer and embedded ones. Developing new programs for these new archictectures is not easy: the developer needs to correctly decompose the application in order to enhance its performance and in order to exploit the multiple processing elements available.Currently, PandA can accept specification written in a pure C code. To support the parsing of the code and the integration of different compiler optimizations, it was decided to adopt the front-end capabilities of the GNU GCC compiler (http://gcc.gnu.org/). From the version 3.5, the GCC front-end parses the source language and produces GENERIC trees, which are then turned into GIMPLE, a simple intermediate representation that leverage the designer from many details of the code. At the moment, PandA front-end is based on the intermediate representation generated by the GCC ver 4.5/4.6/4.7.
The first intermediate representation, GENERIC, is a common representation, language independent, used to serve as an interface between the parser and the optimizer. GIMPLE is also a language independent, tree based representation of the source specification but it is used for target and language independent optimizations (e.g., inlining, constant propagation, tail call elimination, redundancy elimination, etc). With respect to GENERIC, GIMPLE is more restrictive, since its expressions has no more than three operands, it has no control flow structures (everything is lowered to gotos) and expressions with side-effects are only allowed on the right hand side of the assignments. Although GIMPLE has no control flow structures, GCC also builds the control flow graph (CFG) to perform language independent optimizations. All these data are what we need to perform a static analysis of the design specification code. Instead of integrating PandA in GCC we follow a modular design style. In fact, we save in an ASCII file the GIMPLE data structure by exploiting the debugging features of GCC (i.e., the -fdump-tree-oplower-raw GCC option). Actually, the dump performed with this option is performed on a per function basis and therefore several GIMPLE tree nodes are unnecessarily duplicated. To avoid this problem we have slightly modified the tree dump functions of GCC removing some duplication and simplifying the format of the ASCII file. Following the grammar of these files we build a parser able to rebuild the GIMPLE data structure into the PandA framework, thus allowing an independent analysis of the GCC data structures. Obviously, the extraction of GIMPLE information from GCC introduces some overheads but it also allows a modular decoupling between the GCC compiler and our toolset. The GCC analysis and the GIMPLE parsing corresponds to the first two steps performed by the PandA framework to analyze the design specification.
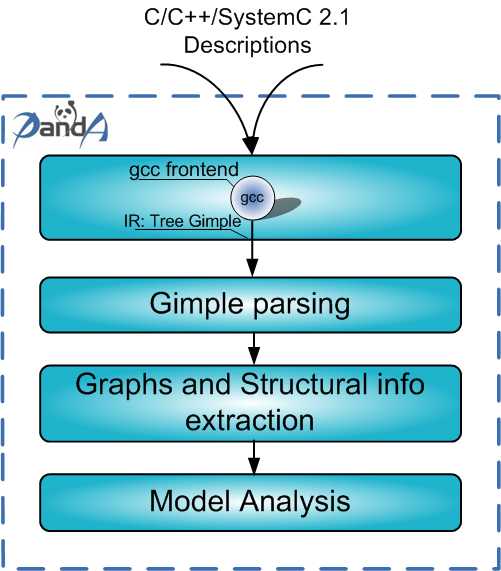
The next step, Graphs and Structural info extraction, builds a layer of functions and data structures providing for
The CFG, the same extracted from the GCC, represents the sequencing of the operations as described in the language specification. Each CFG node has an identifier, the list of variables read and written and has a reference to the corresponding GIMPLE node. Call functions are also associated with the identifier of the called functions, if present in the specification (i.e., they are not system directives or undefined symbols). Moreover, it is worth noting that this representation is collected right after all the (activated) compiler optimizations, just before the target-dependent ones, and it is represented in the Static Single Assignment (SSA) form. This greatly improves the quality of the produced modules by avoiding a conservative approach about, for example, the liveness of the variables and, thus, simplifying the analysis algorithms.
Given this information, a data dependency analysis is performed to identify the correlation between variable uses and definitions. In addition to control and data flow graph, other graphs have also been analysed, such has the system dependency graph (SDG). In particular, PandA includes a high-level synthesizer which exploits the intrinsic parallelism of this intermediate representation. All graphs related to a function in the initial specification are managed by a function_behavior while the structural information is collected in a structural_manager.
To accomplish this task the PandA project has been designed in a modular way. Its structure in fact is composed of several sub-projects that highly interact together:
PandA Sub-projects are described in PandA Tools and Libraries.
PandA's developers should read the following sections:
 1.8.13
1.8.13