 |
PandA-2024.02
|
|
PandA-2024.02
|
Given a data path  , a scheduled DFG
, a scheduled DFG  and a module library
and a module library  :
:
Module allocation: the module allocation function  , determines which module performs a given operation.
, determines which module performs a given operation.
Note that a module allocation  can only be a valid allocation if
can only be a valid allocation if  , i.e. the module
, i.e. the module  is capable of execution of operation type of
is capable of execution of operation type of  .
.
Module binding: a resource binding is a mapping  , where
, where  denotes that the operation corresponding to
denotes that the operation corresponding to  , with type
, with type  (i.e. component
(i.e. component  can execute the operation represented by vertex
can execute the operation represented by vertex  ), is executed on the component
), is executed on the component  and
and  (i.e. the operation is implemented by the r-th instance of resource type
(i.e. the operation is implemented by the r-th instance of resource type  and this instance is available into datapath).
and this instance is available into datapath).
A simple case of binding is a dedicated resource. Each operation is bound to one resource, and the resource binding  is a one-to-one function.
is a one-to-one function.
A resource binding may associate one instance of a resource type to more than one operation. In this case, that particular resource is shared and binding is a many-to-one function. A necessary condition for a resource binding to produce a valid circuit implementation is that the operations corresponding to a shared resource do not execute concurrently, i.e. they are in mutual exclusion.
When binding constraints are specified, a resource binding must be compatible with them. In particular, a partial binding may be part of the original specification, as described in Binding constraints. This corresponds to specifying a binding for a subset of the operations  . A resource binding is compatible with a partial binding when its restriction to the operations
. A resource binding is compatible with a partial binding when its restriction to the operations  is identical to the partial binding itself.
is identical to the partial binding itself.
The module allocation is one of subproblems which high level synthesis problem is decomposed in. Here you focus on assignement of modules to all operations into data path.
First, it's fundamental to give some general definition about module allocation problem and then analyse this and corresponding algorithms implemented.
Given a data path DP  , a scheduled DFG and a module library
, a scheduled DFG and a module library  :
:
 determines which module performs a given operation.
determines which module performs a given operation.Note that a module allocation  can only be a valid allocation if
can only be a valid allocation if  i.e. the module m is capable of execution the operation type of .
i.e. the module m is capable of execution the operation type of .
Module allocation problem can be modeled using a module allocation graph. A compatibility graph  is defined where:
is defined where:
![$Y={ \lbrace (v_i,v_j)\mid (\theta (v_i)\cap \theta (v_j)=\emptyset )\vee (m(v_i) \wedge m(v_j)=[0])\wedge \lambda (\tau (v_i)) \cap \lambda (\tau (v_j)) \neq \emptyset \rbrace } $](../../form_48.png)
An edge  is added between two nodes if the two operations they represents can be combined in a single module, i.e. the operations do not have to be executed concurrently (they are scheduled into different steps) or are mutually exclusive and there exists a module that can perform both operations.
is added between two nodes if the two operations they represents can be combined in a single module, i.e. the operations do not have to be executed concurrently (they are scheduled into different steps) or are mutually exclusive and there exists a module that can perform both operations.
Despite the fact that the register allocation and module allocation look fairy similar there are some differences. In the register allocation it was quietly assumed that all values could be merged in a register. This may not be the case if registers of different bitwidth are considered. But even in this case the transitivity property remains. If value a and b can be fit into a register and so do b and c, also a and c will fit since there has to be a register of size at least the maximum width of a, b and c. In module allocation this is not necessary the case. certain restrictions are imposed on the schedule, module allocation can become considerable simpler. If the schedule does not contain operations that are scheduled over multiple cycle steps (multicycling), this will be called a simple schedule. A data flow graph that does not contain conditional branches will be called an unconditional data flow graph.
First, some library definitions and proprieties on high level synthesies problem can be given.
The data flow graph (graph_manager::DFG) describes the input design to a high level synthesis system. A system needs also information on which modules can be used during the synthesis. A collection of these modules are represented by a library. It is common to use a set of modules each of which can only execute a limited set of operations. The library provides a way to describe the relation between the types of operations and the modules.
The library  is definited by a set of operation types T and the set of components L. The library function
is definited by a set of operation types T and the set of components L. The library function  , determines for each operation type
, determines for each operation type  by which components it can be performed. So the function
by which components it can be performed. So the function  describes for each component which types of operations it can execute. The set
describes for each component which types of operations it can execute. The set  will be called operation type set of l. Operations whose type belong to the same operation type set can share a module (there is a module that can perform both).
will be called operation type set of l. Operations whose type belong to the same operation type set can share a module (there is a module that can perform both).
The operation type set function  , gives for each library component
, gives for each library component  , which operation types it can execute. The sets
, which operation types it can execute. The sets  will be called the operation type sets of the library
will be called the operation type sets of the library  .
.
A library  is called a ordered library, if the operation type sets of form a partial ordering by the set inclusion relation, where all maximal sets are disjunct, which means that all the maximal sets have not a operation type that can be performed by two different maximal components.
is called a ordered library, if the operation type sets of form a partial ordering by the set inclusion relation, where all maximal sets are disjunct, which means that all the maximal sets have not a operation type that can be performed by two different maximal components.
An ordered set can be depicted conveniently by a Hasse diagram (performed in technology_manager::check_library), in which each element is represented by a point, so placed that if  , the point representing X lies below the point representing Y. Lines are drawn to connect sets of X and Y such that Y covers X, i.e. and there is not set Z such that
, the point representing X lies below the point representing Y. Lines are drawn to connect sets of X and Y such that Y covers X, i.e. and there is not set Z such that  ; this is implemented by a directed (covering) edge in a look-like Hasse diagram. A subset is maximal if it's not covered by any other and so it's maximal if it hasn't any incoming edge.
; this is implemented by a directed (covering) edge in a look-like Hasse diagram. A subset is maximal if it's not covered by any other and so it's maximal if it hasn't any incoming edge.
A library is called complete if the library is ordered and has only one maximal set.
A library is called ordered with respect to a DFG, if all the operation types in DFG are an element of one of the maximal operation type sets. Similary, a library is called complete with respect to a DFG, if the maximal operation type set (it's only one) contains all operation types in the DFG. In the remainder of this description the terms complete and ordered libreries will always be used with respect to a DFG.
Now, how a library can impact on module allocation graphs should be analysed.
First, it could be useful to remember most important properties of comparability graphs.
An undirected graph  is called a comparability graph if each edge can be assigned a one way direction, in such a way that the resulting oriented graph
is called a comparability graph if each edge can be assigned a one way direction, in such a way that the resulting oriented graph  satisfies the following condition:
satisfies the following condition:
![$[v_i,v_j]\in T \wedge [v_j,v_k]\in T \Rightarrow [v_i,v_k]\in T$](../../form_64.png)

Comparability graphs are often called transitivity orientable graphs. A relation is called a partial ordering of a set A, when it is reflexive, anti-symmetric and transitive. The relation T is a partial ordering defined on a set V, called the transitive orientation of G.
A module allocation graph derived from an unconditional DFG with a simple schedule and a complete library is a comparability graph (and so it's transitive and orientable).
A module allocation graph derived from and unconditional DFG with a simple schedule and an ordered library is a comparability graph.
Since the library is ordered the composition will result in a module allocation graph consisting of m disjoint comparability graphs, where m is the number of maximal operation types sets in the library of which elements are present in the data flow graphs. In fact flow_allocation can be applied to separated flow network, one for each operation type sets (module_binding::net_flow, passing operation type as a parameter)
A module allocation graphs derived from a DFG with a schedule with property the when operations from a branch are scheduled in the same cycle steps with operations from at most one of its successors branches, and an ordered library, is a comparability graphs.
That's why in module_binding::create_graph has been performed a check is DFG contains or not only nested conditional operations; in fact, these algorithms can operate also with conditional operations, only if there are not nested.
We start from a schedule applied before and then operations are been pre-allocated by algorithms choosen before. The result is a sequence of scheduled operations, with an initial allocation to operation type sets representing functional units that are in technology library.
Module allocation in isolation deals with minimizing the number of operational modules. Now the problem is to improve this module allocation with algorithms exploiting some operation proprieties or considering other aspects of data path allocation. Examples are cost modules or their interconnections. For example, operations can be combined with similar inputs and outputs to reduce the interconnections. Source and destinations of values therefore have to be known. If Register allocation has been performed most inputs and outputs values to the operations are known. So operations can be relocated if results are stored in (or inputs come from) same registers and put in the same functional unit module: this has been implemented in module_binding::weighted_allocation (an algorithm based on progressive thresholds) and module_binding::flow_allocation (flow networks to resolve module allocation problem) with different algorithms.
To model preferences in sharing of operations, weight categories can be assigned to edges in the comparability graph. The edge weight is a measure for the number of common inputs and outputs two operations have (performed in module_binding::create_graph while it's going to create graph). Since the operation nodes are not yet allocated, only the inputs and outputs that have the same operation as origin and destination can be counted. That's been implemented in two different version of module_binding::get_reg_op, one for inputs (reading GET_VAR_READ list) and one for outputs (reading GET_VAR_WRITTEN list).
An heuristic algorithm can be used to find the cliques in a weighted graph. The heuristic presented in module_binding::minimal_clique can be extended. Let  be a graph induced by the edges with weight larger than or equal to the threshold value th. A clique covering is done on this
be a graph induced by the edges with weight larger than or equal to the threshold value th. A clique covering is done on this  . Vertices which form a clique in will be combined in G. Appropriate edges are removed and the weights are update. A new graph is induced with a lower value for the threshold. This process iterates until no new cliques are found and the threshold is low enough to include all remaining edges.
. Vertices which form a clique in will be combined in G. Appropriate edges are removed and the weights are update. A new graph is induced with a lower value for the threshold. This process iterates until no new cliques are found and the threshold is low enough to include all remaining edges.
This algorithm has been implemented in module_binding::clique_cover as follow
The allocation graph is  (where V is set of clique-vertices and E is set of edges) and
(where V is set of clique-vertices and E is set of edges) and  is comparability graph (where T is his set of operation-vertices and R is his set of edges):
is comparability graph (where T is his set of operation-vertices and R is his set of edges):

See Example and corresponding resolution with threshold algorithm
This heuristic will give no guarantee for optimality of the results. In the case of comparability graphs another technique can be employed.
Comparability graphs are per definition transitively orientable. If a path  exists, the edge
exists, the edge  is guaranteed to exist as well. Each path in the graph will therefore be a clique. So the reminder of this section will describe how to transform the weighted module allocation problem to network flow problem. The transformation to the network flow is a transformation generally valid for comparability graphs. It can therefore be used in the other allocation phases as well.
is guaranteed to exist as well. Each path in the graph will therefore be a clique. So the reminder of this section will describe how to transform the weighted module allocation problem to network flow problem. The transformation to the network flow is a transformation generally valid for comparability graphs. It can therefore be used in the other allocation phases as well.
Consider the weighted module allocation graph  . Furthermore, a source node a, a sink node z, edges from source node to all nodes, edges from all nodes to the sink node and an edge from the sink to the source are added. The edge from the sink to the source is called the return edge, The weight of all these additional edges is zero.
. Furthermore, a source node a, a sink node z, edges from source node to all nodes, edges from all nodes to the sink node and an edge from the sink to the source are added. The edge from the sink to the source is called the return edge, The weight of all these additional edges is zero.
Formally, a network  corresponding to the module allocation graph is constructed, where:
corresponding to the module allocation graph is constructed, where:
 .
.![$ E_n=T \cup \lbrace [a,v],[v,z] \mid v \in V_o \rbrace \cup \lbrace [z,a] \rbrace $](../../form_76.png) .
. .
.For each edge  a cost function
a cost function  is defined, which assigns to each edge a non-negative integer. The cost will be equal to the weight of the edges:
is defined, which assigns to each edge a non-negative integer. The cost will be equal to the weight of the edges: ![$ C([u,v])=w(u,c) $](../../form_80.png) for all
for all ![$ [u,v] \in E_n $](../../form_81.png) .
.
For each edge a capacity function  is defined, which assigns to each edge a non-negative integer. The capacity of all edges is one, except for the return edge which has capacity k:
is defined, which assigns to each edge a non-negative integer. The capacity of all edges is one, except for the return edge which has capacity k: ![$ K([z,a])=k, \ \ \ \ \ \ \ \ \ \ \ K([u,v])=1 \ \ \ \ \forall [u,v] \in E_n \setminus \lbrace [z,a] \rbrace $](../../form_83.png) .
.
A flow in the network  is a function
is a function  , which assigns to each edge a non-negative integer, such that for
, which assigns to each edge a non-negative integer, such that for  and for any node
and for any node 
![$ \sum _{[u,v]\in E_n} f(u,v) - \sum _{[v,u]\in E_n} f(v,u) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ $](../../form_88.png) balancing equation
balancing equation
The amount of flow in the return edge ![$ [z,a] $](../../form_89.png) is denoted as
is denoted as ![$ F=f([z,a]) $](../../form_90.png) . The total cost of the flow is:
. The total cost of the flow is:  .
.
A flow  , in the network corresponds to a set of cliques
, in the network corresponds to a set of cliques  in G_o where
in G_o where  .
.
The paths  will be edge disjoint (each edge has only capacity=1), but not necessarily go through different nodes (in a node can enter/exit more than one edge). Thus the sets are not necessarily node disjoint (a node can be in different cliques, so can be allocated into different modules).
will be edge disjoint (each edge has only capacity=1), but not necessarily go through different nodes (in a node can enter/exit more than one edge). Thus the sets are not necessarily node disjoint (a node can be in different cliques, so can be allocated into different modules).
To enforce node disjoint paths, a node separation technique can be used. In the node separation, all nodes  are duplicated. The duplicate of a node
are duplicated. The duplicate of a node  is called
is called  . All edges outgoing from , obtain the node as their origin. The node and its duplicate are connected by an edge with capacity
. All edges outgoing from , obtain the node as their origin. The node and its duplicate are connected by an edge with capacity ![$ K([v,v'])=1 $](../../form_99.png) (only one unit flow can go through) and a cost
(only one unit flow can go through) and a cost ![$ C([v,v'])=0 $](../../form_100.png) (no additional solution cost). This node separation results in a network
(no additional solution cost). This node separation results in a network  , where:
, where:

 for each vertex
for each vertex ![$ E'_n=T \cup \lbrace [a,v],[v',z] \mid v \in V_o \rbrace \ \ \cup \ \ \lbrace [z,a] \rbrace \cup \lbrace [v,v']\mid v\in V_o \rbrace $](../../form_104.png)
![$ T' = \lbrace [v',u]\mid [v,u] \in T\rbrace $](../../form_105.png)
![$ C'([z,a])=C'([v,v']) = 0 \ \ \ \ \ \forall v \in V_o \ \ \ \ $](../../form_106.png) (no additional cost for support edges)
(no additional cost for support edges)![$ C'([v',u])=C([v,u]) \ \ \ \ \forall [v,v'] \in T' \cup \lbrace [a,v],[v',z]\mid v \in V_o $](../../form_107.png)
![$ K'([z,a])=k \ \ \ \ \ \ \ \ \ K'([u,v])=1 \ \ \ \ \ \ \forall u \neq z \wedge v \neq a $](../../form_108.png)
Since the capacity of at most one unit of flow can go through the edge [v,v']. This leads to the following theorem:
A flow  , in the network
, in the network  corresponds to a set of node disjoint cliques in
corresponds to a set of node disjoint cliques in  where .
where .
The maximal cost network flow problem finds among all possible flows with amount k the one with maximum cost. This has been implemented in module_binding::maxcost_minflow function, where you can find a way to resolve maxcost flow with a positive cycles elimination. In fact, whenever you can find a positive cycle in the residual network flow, the solution can be incremented over this one and the new solution will be always better. So, if no positive cycles can be found, a better the solution cannot be found and the flow obtained is the maxcost one.
In this situation, a triple  is given where
is given where  is a directed graph with n vertices and m edges,
is a directed graph with n vertices and m edges,  is a lenght function mapping edges to integer lenghts and
is a lenght function mapping edges to integer lenghts and  in the root vertex. The lenght of the path
in the root vertex. The lenght of the path  is the sum of lenghts of its constituent edges (take it negative if the edge is a flow edge due to residual definition graph). So positive cycle is a cycle
is the sum of lenghts of its constituent edges (take it negative if the edge is a flow edge due to residual definition graph). So positive cycle is a cycle  with lenght
with lenght  . Algorithms for PCD (positive cycle detection) that use the adjacency-list representation of the graph construct a longest-path tree
. Algorithms for PCD (positive cycle detection) that use the adjacency-list representation of the graph construct a longest-path tree  , where
, where  is the set of all vertices reachable from the root s,
is the set of all vertices reachable from the root s,  , s is the root of
, s is the root of  and for every vertex
and for every vertex  the path from s to v in is a longest path from s to v in G.
the path from s to v in is a longest path from s to v in G.
The labeling method maintains for every vertex v its distance label  and parent
and parent  . Initially
. Initially  and
and  . The method is based on the scan operation. During scanning a vertex v, all edges
. The method is based on the scan operation. During scanning a vertex v, all edges  out-going from v are relaxed which means that if
out-going from v are relaxed which means that if  then
then  is set to
is set to  and
and  is set to v. If all vertices have been scanned then d gives the longest path lenghts and
is set to v. If all vertices have been scanned then d gives the longest path lenghts and  (parent graph induced by edges
(parent graph induced by edges  ) is the longest path tree. So, if there is a cycle, after a finite number of scan operations (
) is the longest path tree. So, if there is a cycle, after a finite number of scan operations (  is upper bound) you can detect it; in fact, starting from a vertex
is upper bound) you can detect it; in fact, starting from a vertex  , if the same vertex is in parent tree, it means that there is a (positive) path from to , so there is a cycle.
, if the same vertex is in parent tree, it means that there is a (positive) path from to , so there is a cycle.
Once detected a positive cycle, the flow on positive edges is increased and the flow on negative ones is decremented. So cycle is eliminated and solution cost will be better. If any positive cycle can be detected, there is no way to improve solution and this will be the best one (maximum cost solution).
See Example and corresponding resolution with flow network
When the maximal cost network flow is solved for the network , a solution to the module allocation problem is found, which takes into account the first order effects of interconnection weights. These first order effects describe the result of combining each pair of operations. Taking into account the influence of this combination on the weights with a third operation, would require a dynamic update of the edge weights due to the cumulative nature of the costs. This aspect has not been implemeted yet in this project.
For example, having this DFG:
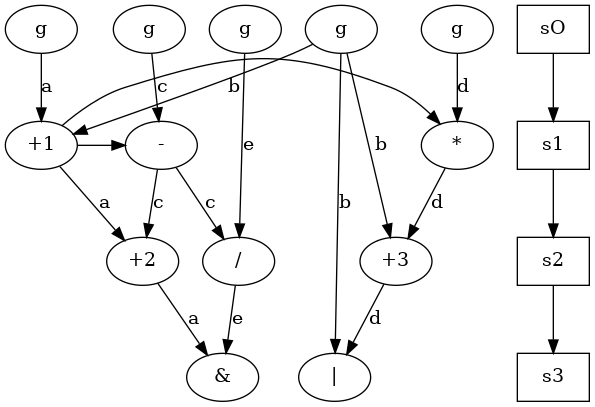
where egde label is register name where variable is stored and g are inputs.
Assuming a library with two functional unit types, one that can implement  and the other that implements
and the other that implements  , comparability graph has to be created, according to definition given above (they are scheduled into different steps or they are in exclusive paths, they can be executed by same functional unit type).
, comparability graph has to be created, according to definition given above (they are scheduled into different steps or they are in exclusive paths, they can be executed by same functional unit type).
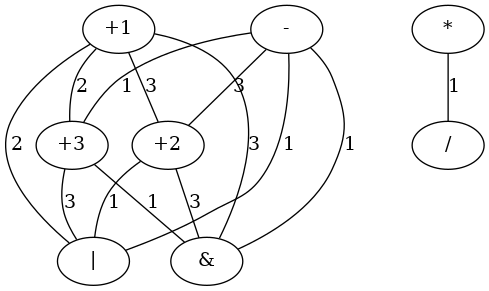
Edge label is weight value: number of commun inputs and outputs. For example, edge  has
has  . In fact, assuming
. In fact, assuming  as base, that means only one common input or output: that is register
as base, that means only one common input or output: that is register  that is a common input: both read from this one. Edge
that is a common input: both read from this one. Edge  has a common input (they read both from register
has a common input (they read both from register  ) and a common output (they write both to register ); so it has
) and a common output (they write both to register ); so it has  . Now, cliques have to be found in this (weighted) graph. It's important to notice that to do this a schedule and an assignement to functional units types have to be provided. These are provided by HLS class.
. Now, cliques have to be found in this (weighted) graph. It's important to notice that to do this a schedule and an assignement to functional units types have to be provided. These are provided by HLS class.
On the example above, threshold algorithm can be applied as described.
First maximum threshold is  and so graph induced is:
and so graph induced is:
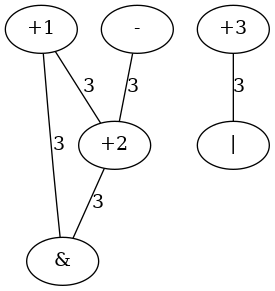
where, applying clique covering, three clique can be found:  ,
,  and
and  . So the comparability graph modified collapsing nodes and updating egdes (an edge remains if there was an edge beetween the node and each node in the new clique) is:
. So the comparability graph modified collapsing nodes and updating egdes (an edge remains if there was an edge beetween the node and each node in the new clique) is:
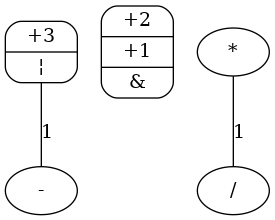
Now the choose to compute maximum threshold is shown to be efficent. In fact, there is not any edge so the computation is applied with  . The graph induced is the same (no edge is eliminated):
. The graph induced is the same (no edge is eliminated):
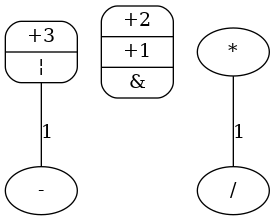
and two new clique are found:  and . So, the new (and final) comparability graph is:
and . So, the new (and final) comparability graph is:
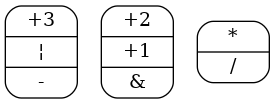
No edge is left and so vertices are definitive cliques. Each clique can be assigned to a module. So, operations with weighter edges are prefered to be assigned to same module.
On example above, there is not any nested conditional operation and so the compatility graph is orientable (it becomes a comparability graph). Thus a flow network for each FU type can be created as well. In according to definition given in subsection flow networks to resolve module allocation problem, the flow network for FU type for resulting is:
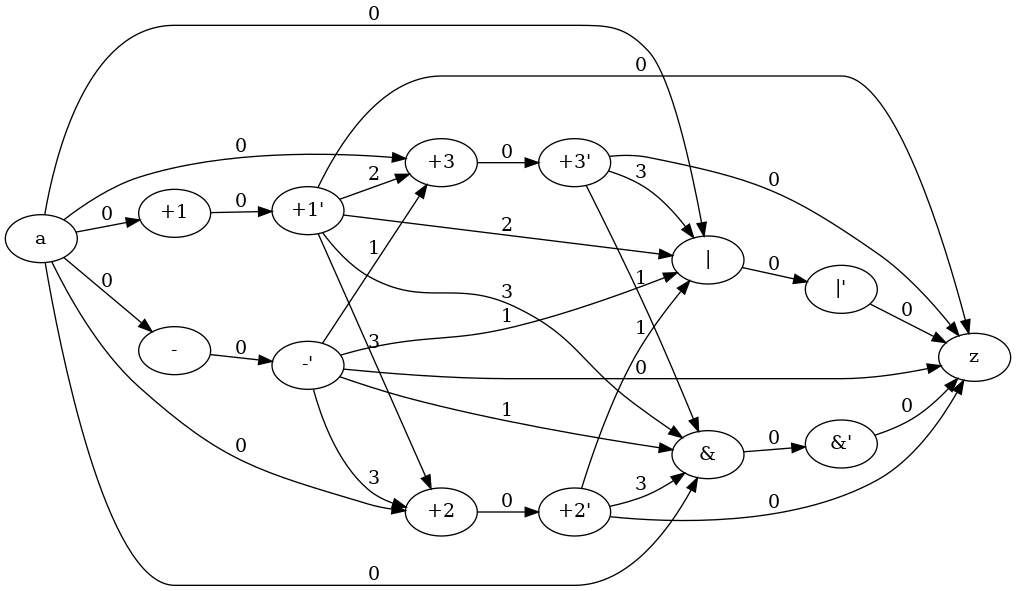
A dummy initial flow can be applied and corresponding residual graph will be:
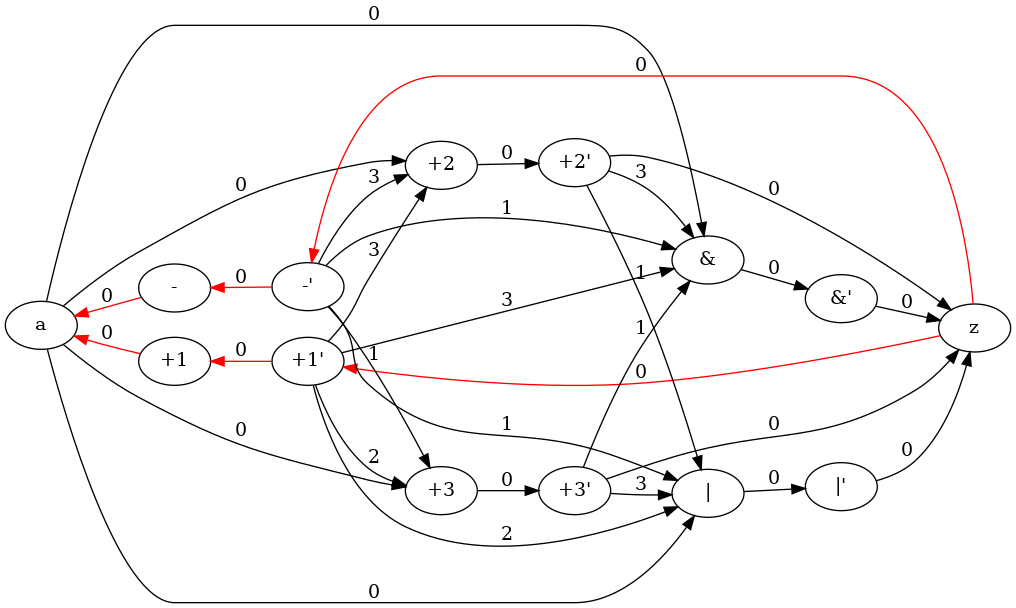
In this way, it's simple to find a better solution. When a positive cycle has been found (for example  and
and  , the flow can be increased on direct edge and decreased in return edge. Thus solution would be better (from
, the flow can be increased on direct edge and decreased in return edge. Thus solution would be better (from  to
to  ):
):
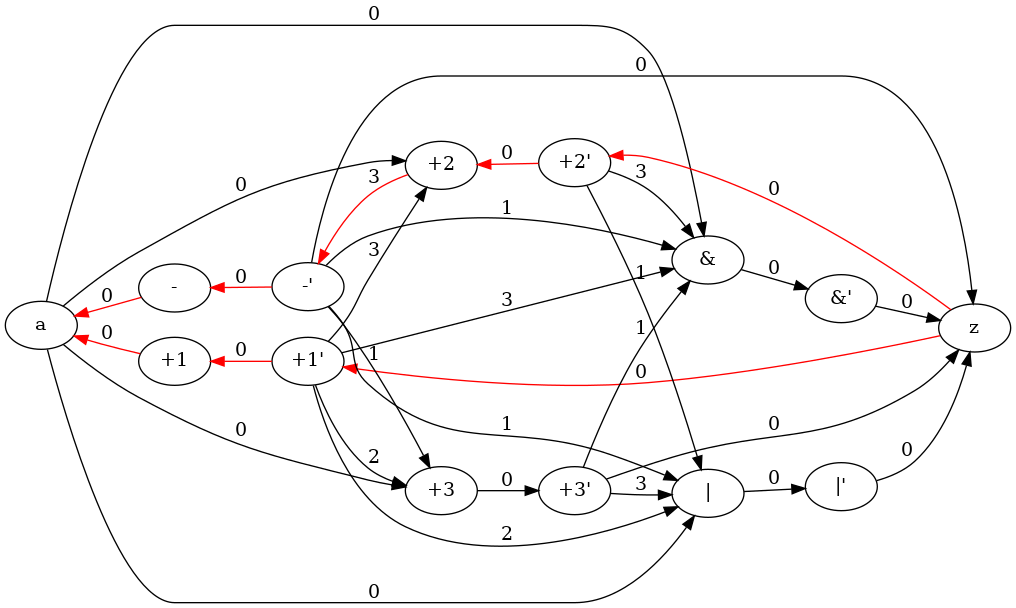
When no more positive cycles can be found, the solution is optimal for this network and the paths from source to sink will be the max cost partitioning for operation vertices present in this graph. This algorithm have to be applied to all functional units type the library consists in.
 1.8.13
1.8.13